На перший погляд, результати METR здаються суперечливими з іншими дослідженнями та експериментами, які демонструють підвищення ефективності програмування за використання інструментів штучного інтелекту. Однак останні зазвичай оцінюють продуктивність за загальною кількістю рядків коду або кількістю виконаних завдань, що можуть бути ненадійними показниками реальної ефективності коду.
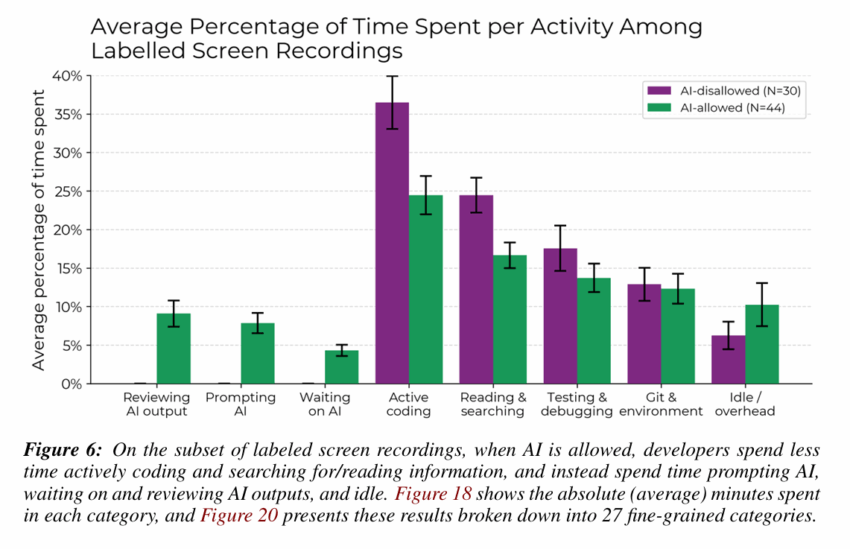
Багато існуючих стандартів програмування також зосереджуються на синтетичних завданнях, створених спеціально для тестів, тому важко зіставити ці результати з даними, пов’язаними з вже існуючими реальними кодовими базами. У дослідженні METR розробники повідомили у своїх опитуваннях, що загальна складність репозиторіїв, з якими вони працюють (середній вік понад 10 років та більше 1 мільйона рядків коду), обмежувала корисність штучного інтелекту. Дослідники зазначають, що штучний інтелект не зміг використовувати “важливі неявні знання або контекст” коду, тоді як “висока знайомість розробників з репозиторіями” сприяла їхній продуктивності.
Ці фактори призвели дослідників до висновку, що сучасні інструменти штучного інтелекту можуть бути особливо неефективні в “середовищах з дуже високими стандартами якості або з численними неявними вимогами, такими як документація, покриття тестами або контроль за оформленням, які потребують значного часу для навчання у людей”. Хоча це може не бути актуальним у “багатьох реалістичних економічно важливих ситуаціях”, пов’язаних з простішими кодовими базами, це може обмежити вплив інструментів штучного інтелекту в даному дослідженні та подібних реальних ситуаціях.
Навіть для складних проектів програмування, які були предметом вивчення, дослідники також оптимістично налаштовані на вдосконалення інструментів штучного інтелекту, що може призвести до майбутнього підвищення ефективності для програмістів. Системи з кращою надійністю, меншими затримками або більш релевантними результатами (завдяки технікам, таким як структуризація запитів або доопрацювання) “могли б пришвидшити розробників у нашому середовищі”, пишуть дослідники. Вони також зазначають, що вже є “попередні докази” того, що нещодавній реліз Claude 3.7 “часто може правильно реалізувати основну функціональність завдань у кількох репозиторіях, які включено в наше дослідження”.
Проте, поки що, дослідження METR надає переконливі докази того, що широко рекламована корисність штучного інтелекту для програмних завдань може мати значні обмеження в деяких складних реальних сценаріях програмування.